
A friend needed a portfolio site. Marcus is an actor — credits on Netflix, smaller European productions, the kind of career where your work is scattered across databases that nobody outside the industry checks. He had no web presence beyond what casting platforms gave him.
Two things, one session
The goal: build the portfolio site, then enrich his Wikidata entry so the knowledge graph actually reflects his career.
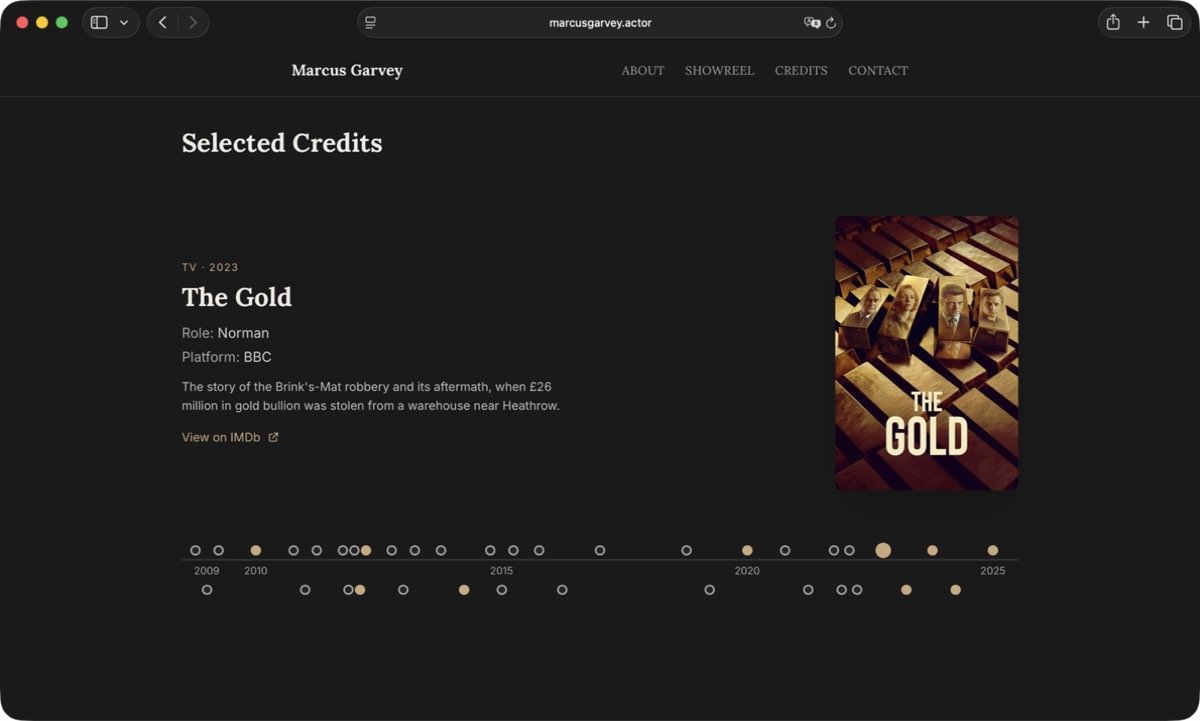
The site came together fast. Astro with Tailwind, single-page layout, an interactive hover timeline instead of a traditional credits table — fifteen productions, each revealing a production still on hover with a title overlay. The SEO stack went in alongside: JSON-LD Person and PerformanceRole schema, OG tags, Twitter Cards, llms.txt, sitemap. For images, I sourced a headshot for the hero, a press still from one major production, and TMDB backdrops for the rest. In supporting roles, press kits rarely feature you — production backdrops are the practical stand-in.
For Wikidata, I built a reusable Python tool using wikibaseintegrator to replace a browser automation workflow that was slower and more fragile. The plan: remove three incorrect music IDs (wrong person, same name), add birthplace, citizenship, education, fifteen notable works with character qualifiers, and update his description.
Sixteen out of seventeen
The first batch of Wikidata edits included Q-numbers — the unique identifiers for every entity in the knowledge base. Film titles, production companies, educational institutions. Out of 17 Q-numbers in that first pass, 16 were fabricated. The AI had generated plausible-looking identifiers that pointed to nothing, or worse, to the wrong entities entirely.
The verification rule caught them. Every Q-number got checked against the live API before writing. All 16 fakes were flagged, replaced with real identifiers, and the edits went through clean.
The tool was designed with a check-before-write step not because I expected failure, but because writing incorrect data to a public knowledge base is the kind of mistake you cannot easily undo. The verification step cost seconds. Skipping it would have cost hours of cleanup — and damaged a real person’s public record.
The check-before-write is the product
Verification is a feature, not a safety net. When your system writes to shared infrastructure — a knowledge base, a public API, a production database — the check-before-write step earns its place every time. Build it in from the start, and a 94% failure rate on the first batch becomes a quiet non-event instead of a public correction.
Site to deployed prototype, Wikidata entry corrected and enriched, reusable tool for future use — under three hours. The boring verification step was what made the speed safe.